Итак, поворотный момент в истории компании "Лифт ми Ап". Руководство понимает, что компания, производящая лифты, едущие только вверх, не выдержит борьбы на высококонкурентном рынке. Необходимо расширять бизнес. Принято решение о покупке двух заводов: в Санкт-Петербурге и Кемерово.
Нужно срочно организовывать связь до новых офисов, а у вас ещё даже локалка не заработала.
Сегодня:
1. Настраиваем маршрутизацию между вланами в нашей сети (InterVlan routing)
2. Пытаемся разобраться с процессами, происходящими в сети, и что творится с данными.
3. Планируем расширение сети (IP-адреса, вланы, таблицы коммутации)
4. Настраиваем статическую маршрутизацию и разбираемся, как она работает.
5. Используем L3-коммутатор в качестве шлюза
В то же время они более чувствительны к изменениям в сети. Он распределяется, потому что каждый узел получает некоторую информацию о том, что один или несколько соседей напрямую связаны, вычисляет, а затем распределяет результаты своих вычислений своим соседям. Интерактив происходит из-за постоянного обмена данными, пока уже невозможно сделать такой обмен. И асинхронный, поскольку он не требует одновременного запуска всех узлов.
Алгоритмы маршрутизации, которые используют вектор расстояний, работают так, чтобы каждый маршрутизатор поддерживал таблицу, которая обеспечивает наиболее известное расстояние до пункта назначения, а также указывает, какая строка должна использоваться для передачи. Такие таблицы обновляются путем обмена информацией с соседями.
В данный момент (вспомним ) у нас в Москве использованы адреса 172.16.0.0-172.16.6.255. Предположим, что сеть может ещё увеличиться здесь, допустим, появится офис на Воробьёвых горах и зарезервируем ещё подсети до 172.16.15.0/24 включительно.
Все эти адреса: 172.16.0.0-172.16.15.255 - можно описать так: 172.16.0.0/20. Эта сеть (с префиксом /20) будет так называемой суперсетью
, а операция объединения подсетей в суперсети называется суммированием
подсетей (суммированием маршрутов, если быть точным, route summarization)
В маршрутной маршрутизации на расстоянии каждый маршрутизатор поддерживает таблицу маршрутизации, индексированную каждым маршрутизатором в подсети, и содержит входные данные для каждого из этих маршрутизаторов. Вход состоит из двух частей: используемой выходной линии и оценки времени или расстояния до конечной точки.
Можно сказать, что метод вектор расстояний функционирует теоретически, однако на практике представляет собой серьезную проблему: его сходимость может быть медленной. «В частности, он быстро реагирует на хорошие новости, но медленно реагирует на плохие новости».
Приносим извинения за гигантские простыни, видео тоже с каждым разом становится всё длиннее и невыносимее. Постараемся в следующий раз быть более компактными.
Все заинтересованные, но незарегистрированные приглашаются на беседу в .
За подготовку статьи большое спасибо моему соавтору и моей жене за львиное терпение.
Для очень недовольных: эта статья не абсолют, она не раскрывает теоретические аспекты в полной мере и, потому не претендует на роль полноценной документации. С точки зрения авторов это вспомогательной средство для новичков, волшебный стимул, если желаете. На хабре у вас есть возможность поставить минус, а не доказывать нашу неправоту. Прошу вас, поступите именно так, потому что ваши недовольства встретят лишь вышеприведённые аргументы.
Чтобы проверить, как быстро вектор расстояний реагирует на хорошие новости, рассмотрите подсеть из пяти узлов, как показано на рисунке. В этом примере используемой метрической единицей является количество переходов. Уже когда А становится активным, другие маршрутизаторы будут знать об этом через векторный обмен. Рисунок 6: Учет проблемы до бесконечности.
Источник. Теперь рассмотрим изображение справа. Чтобы проверить, насколько быстро вектор расстояний реагирует на хорошие новости, рассмотрите подсеть с пятью узлами на рисунке. В этом примере используется метрическая единица - количество переходов. С помощью того, что было показано в предыдущем абзаце, считается, что плохие новости имеют медленное распространение. Ни один маршрутизатор не имеет значения больше единицы, чем минимальное значение для всех его соседей. Постепенно все маршрутизаторы идут в бесконечность, но количество требуемых обменов зависит от численного значения, используемого для бесконечности.
Мальчик сказал маме: “Я хочу кушать”. Мама отправила его к папе.
Мальчик сказал папе: “Я хочу кушать”. Папа отправил его к маме.
Мальчик сказал маме: “Я хочу кушать”. Мама отправила его к папе.
И бегал так мальчик, пока в один момент не упал.
Что случилось с мальчиком? TTL кончился.
Итак, поворотный момент в истории компании “Лифт ми Ап”. Руководство понимает, что компания, производящая лифты, едущие только вверх, не выдержит борьбы на высококонкурентном рынке. Необходимо расширять бизнес. Принято решение о покупке двух заводов: в Санкт-Петербурге и Кемерово.
Нужно срочно организовывать связь до новых офисов, а у вас ещё даже локалка не заработала.
Сегодня:
По этой причине лучше всего определить бесконечность как самый длинный путь и еще одну единицу. Из-за того, что было прокомментировано, счет имени приходит в бесконечность. В дополнение к бесконечной задаче подсчета алгоритм вектора расстояния сохраняет все записи изменений, происходящих в сети, периодически передавая обновления в таблицы маршрутизации для активных интерфейсов.
Алгоритм состояния ссылки имеет знание топологии сети и всех затрат на связь. Это возможно при передаче пакетов каждым из узлов ко всем остальным. Это то, что происходит за счет каждой ссылки. С помощью трансляции состояния канала становится возможным ссылаться на нее.
Содержание:
«Результатом трансляции узлов является то, что все узлы имеют идентичный и полный вид сети». Идея маршрутизации состояния канала проста и может быть установлена как пять частей. Каждый маршрутизатор должен сделать следующее. Узнайте своих соседей и узнайте их сетевые адреса; Измерьте маршрутизатор или стоимость каждого из ваших соседей; Создайте пакет, который расскажет вам все, что он только что узнал; Отправьте этот пакет всем другим маршрутизаторам; Рассчитайте кратчайший путь к каждому из других маршрутизаторов. Когда маршрутизатор запускается, его первым действием является изучение того, кто его соседи.
Процесс настройки маршрутизатора очень прост:
Таким образом, маршрутизатор на другом конце должен отправить ответ, идентифицируя себя. Метод состояния ссылки требует, чтобы каждый маршрутизатор знал задержку для каждого из своих соседей. Таким образом, он использует методологию измерения времени прохождения в оба конца и деления на два. Маршрутизатор может получить разумную оценку от соседа.
Возникает интересный вопрос: следует ли учитывать нагрузку при измерении задержки? Есть аргументы в пользу двух вариантов. Использование нагрузки, когда маршрутизатор должен выбирать между двумя линиями с одинаковой полосой пропускания, будет маршрутом на незаряженной линии, то есть с кратчайшим путем. Это обеспечит превосходную производительность.
0) Сначала закончим с коммутатором msk-arbat-dsw1. На нём нам нужно настроить транковый порт в сторону маршрутизатора, чего мы не сделали в прошлый раз.
Msk-arbat-dsw1(config)#interface FastEthernet0/24
msk-arbat-dsw1(config-if)# description msk-arbat-gw1
msk-arbat-dsw1(config-if)# switchport trunk allowed vlan 2-3,101-104
msk-arbat-dsw1(config-if)# switchport mode trunk
1) Назначаем имя маршрутизатора командой hostname
, а для развития хорошего тона, надо упомянуть, что лучше сразу же настроить время на устройстве. Это поможет вам корректно идентифицировать записи в логах.
Однако есть аргумент, который противоречит включению нагрузки при вычислении задержки. Рисунок 7: Подсеть с двумя частями. Таким образом, этот путь будет страдать от длительных задержек, и связь будет перегружена. Это может привести к колебаниям в таблицах маршрутизации и, таким образом, к потенциальным проблемам. Однако не использовать нагрузку в качестве параметра может привести к тому, что эта проблема не возникнет. Существуют и другие решения, позволяющие избежать такой проблемы, например, распределение нагрузки по нескольким выходным линиям с использованием известной доли нагрузки, используемой при передаче каждой строки.
Router0#clock set 12:34:56 7 august 2012
Router0# conf t
Router0(config)#hostname msk-arbat-gw1
Желательно время на сетевые устройства раздавать через NTP (любую циску можно сделать NTP-сервером, кстати)
Msk-arbat-gw1(config)#interface fastEthernet 0/0
msk-arbat-gw1(config-if)#no shutdown
3) Создадим виртуальный интерфейс или иначе его называют подинтерфейс или ещё сабинтерфейс (sub-interface).
Пакет начинается с идентификатора передатчика, за которым следует порядковый номер по возрасту и списку соседей. Примерная подсеть указана на рисунке, с задержками, отображаемыми как метки строк. Последующие пакеты состояния канала для всех маршрутизаторов находятся на чертеже с задержками, отображаемыми как метки линий.
Основная идея заключается в использовании алгоритма наводнения для распределения пакетов состояния канала. Чтобы иметь возможность контролировать такой алгоритм, каждый пакет содержит порядковый номер, который увеличивается для каждого передаваемого пакета. Роутеры выполняют контроль над всеми сверстниками, которые приходят. При получении новый пакет проверяется в списке отправленных пакетов. Если по какой-либо причине пакет содержит порядковый номер, меньший, чем самый старший порядковый номер, обнаруженный до сих пор, он будет отброшен, потому что маршрутизатор будет иметь более новую информацию.
Msk-arbat-gw1(config)#interface fa0/0.2
msk-arbat-gw1(config-if)#description Management
Логика тут простая. Сначала указываем обычным образом физический интерфейс, к которому подключена нужная сеть, а после точки ставим некий уникальный идентификатор этого виртуального интерфейса. Для удобства, обычно номер сабинтерфейса делают аналогичным влану, который он терминирует.
У упомянутого алгоритма есть некоторые проблемы, но они могут быть решены. Во-первых, если номера последовательностей повторятся, преобладает путаница. Решение состоит в использовании 32-битных порядковых номеров. С пакетом состояния канала в секунду потребуется 137 лет для повторяющегося числа.
Вторая проблема - если маршрутизатор терпит неудачу, он теряет контроль над порядковым номером. Если он снова начнется с нуля, пересылка пакета не произойдет, поскольку считается копией. Третья очевидная проблема заключается в том, что если номер последовательности подделан и число 540 принимается вместо числа 4, пакеты с 5 по 540 будут отклонены как устаревшие, поскольку 540 будет считаться текущим порядковым номером.
4) Теперь вспомним о стандарте 802.1q , который описывает тегирование кадра меткой влана. Следующей командой вы обозначаете, что кадры, исходящие из этого виртуального интерфейса будут помечены тегом 2-го влана. А кадры, входящие на физический интерфейс FastEthernet0/0 с тегом этого влана будут приняты виртуальным интерфейсом FastEthernet0/0.2.
Чтобы решить эти проблемы, он включает возраст в каждом пакете после порядкового номера и уменьшает его один раз в секунду. Таким образом, когда возраст достигнет нуля, информация с этого маршрутизатора будет отброшена. Однако некоторые усовершенствования могут быть добавлены к этому алгоритму, чтобы сделать его более устойчивым. Когда пакет состояния связи поступает на маршрутизатор для наводнения, он не сразу ставится в очередь для передачи. Вместо этого он находится в зоне ожидания, чтобы подождать некоторое время.
Если другой пакет состояния связи из одного источника поступает до передачи первого пакета, его порядковые номера будут сравниваться. Если они совпадают, копия будет отброшена. Если они разные, самые старые будут отброшены. Что касается ошибок в строках между двумя маршрутизаторами, все пакеты состояния канала имеют фиксацию. Когда строка простаивает, область хранения будет перемещаться последовательно, чтобы выбрать пакет или подтверждение для отправки.
Msk-arbat-gw1(config-if)#encapsulation dot1Q 2
5) Ну и как на обычном физическом L3-интерфейсе, определим IP-адрес. Этот адрес будет шлюзом по умолчанию (default gateway) для всех устройств в этом влане.
Msk-arbat-gw1(config-if)#ip address 172.16.1.1 255.255.255.0
Аналогичным образом настроим, например, 101-й влан:
Msk-arbat-gw1(config)#interface FastEthernet0/0.101
msk-arbat-gw1(config-if)#description PTO
msk-arbat-gw1(config-if)#encapsulation dot1Q 101
msk-arbat-gw1(config-if)#ip address 172.16.3.1 255.255.255.0
и теперь убедимся, что с компьютера из сети ПТО мы видим сеть управления: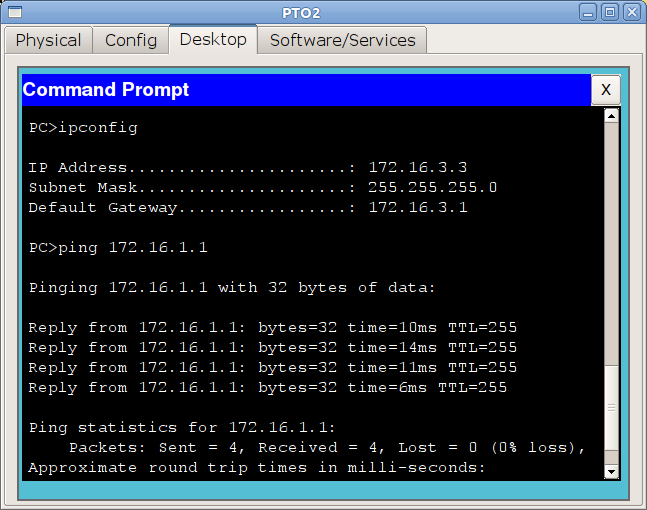
Когда маршрут накапливает полный набор пакетов состояния канала, он может создать полную степень подсети, потому что может быть представлена вся ссылка. Однако вся ссылка представлена дважды, один раз в каждом направлении. Таким образом, алгоритм Дейкстры может выполняться локально, чтобы создать кратчайший путь ко всем возможным назначениям. Результаты этого алгоритма могут быть установлены в таблицах маршрутизации, и нормальная работа может быть возобновлена.
В больших сетях это может стать проблемой. Кроме того, время вычисления также может иметь большое значение. Однако во многих практических действиях маршрутизация каналов связи удовлетворительно работает. В этом документе описаны этапы настройки и устранения неполадок при создании интерфейсов уровня.
Работает и отлично, настройте пока все остальные интерфейсы. Проблем с этим возникнуть не должно.
Все устройства, адреса которых будут находиться в диапазоне 172.16.3.1-172.16.3.254 с такой же маской, как у вас, будут являться членами вашей подсети. Что происходит с данными, если вы отправляете их на устройство с адресом из этого диапазона? Повторим это с некоторыми дополнениями.
Все устройства, используемые в этом документе, начинались с удаленной конфигурации. Если ваша сеть запущена и работает, убедитесь, что вы понимаете эффект потенциал любого порядка. Сценарий можно расширить, включив в него среду с несколькими коммутаторами, если вы сначала настроите и протестируете межключковые соединения по сети, прежде чем настраивать возможности маршрутизации.
Это называется маршрутизацией. «Маршрут» определяется парой адресов: «пункт назначения» и «шлюз». Эта пара означает, что для достижения этого адресата вам необходимо пройти через этот шлюз. Существует три вида назначения: отдельные машины, подсетей и «по умолчанию» - назначение по умолчанию. Маршрут по умолчанию используется, когда другой маршрут не применим. Мы будем говорить немного больше о маршрутах по умолчанию позже.
Для отправки данных они должны быть упакованы в Ethernet-кадр, в заголовок которого должен быть вставлен MAC-адрес удалённого устройства. Но откуда его взять?
Для этого ваш компьютер рассылает широковещательный ARP-запрос. В качестве IP-адреса узла назначения в IP-пакет с этим запросом будет помещён адрес искомого хоста. Сетевая карта при инкапсуляции указывает MAC-адрес FF:FF:FF:FF:FF:FF - это значит, что кадр предназначен всем устройствам. Далее он уходит на ближайший коммутатор и копии рассылаются на все порты нашего влана (ну, кроме, конечно, порта, из которого получен кадр). Получатели видят, что запрос широковещательный и они могут оказаться искомым хостом, поэтому извлекают данные из кадра. Все те устройства, которые не обладают указанным в ARP-запросе IP-адресом, просто игнорируют запрос, а вот устройство-настоящий получатель ответит на него и вышлет первоначальному отправителю свой MAC-адрес. Отправитель (в данном случае, наш компьютер) помещает полученный MAC в свою таблицу соответствия IP и MAC адресов ака ARP-кэш. Как выглядит ARP-кэш на вашем компьютере прямо сейчас, вы можете посмотреть с помощью команды arp -a

Существует также задержка, связанная с этим типом маршрута, которая используется, если вы слышите больше об этом аппарате в течение определенного периода времени. В этом случае маршрут к этому устройству автоматически удаляется. Вы обнаружите, что нет другого интерфейса, связанного с этими дорогами. Эти два типа маршрутов автоматически настраиваются с помощью «демона», называемого маршрутизируемым. Если он не запускается, тогда будут существовать только маршруты, определенные как статические.
Этот тип дороги отображается только на машине, для которой определен псевдоним; на всех других машинах в локальной сети будет только линия связи №1 для этой машины. Последняя строка относится к многоадресной рассылке, которая будет рассмотрена в другом разделе.
Потом ваши полезные данные упаковываются в IP-пакет, где в качестве получателя ставится тот адрес, который вы указали в команде/приложении, затем в Ethernet-кадр, в заголовок которого помещается полученный ARP-запросом MAC-адрес. Далее кадр отправляется на коммутатор, который, согласно своей таблице MAC-адресов, решает, в какой порт его переправить дальше.
Но что происходит, если вы пытаетесь достучаться до устройства в другом влане? ARP-запрос ничего не вернёт, потому что широковещательные L2 сообщения кончаются на маршрутизаторе(т.е., в пределах широковещательного L2 домена), нужная сеть находится за ним, а коммутатор не пустит кадры из одного влана в порт другого. И вот для этого нужен шлюз по умолчанию (default gateway) на вашем компьютере. То есть, если устройство-получатель в вашей же подсети, кадр просто отправляется в порт с мак-адресом конечного получателя. Если же сообщение адресовано в любую другую подсеть, то кадр отправляется на шлюз по умолчанию, поэтому в качестве MAC-адреса получателя подставится MAC-адрес маршрутизатора.
Проследим за ходом событий.
1) ПК с адресом 172.16.3.2/24 хочет отправить данные компьютеру с адресом 172.16.4.5.
Он видит, что адрес из другой подсети, следовательно, данные должны уйти на шлюз по умолчанию. Но в таком случае, ПК нужен MAC-адрес шлюза. ПК проверяет свой ARP-кэш в поисках соответствия IP-адрес шлюза - MAC-адрес и не находит нужного
2) ПК отправляет широковещательный ARP-запрос в локальную сеть. Структура ARP-запроса:
- на канальном уровне в качестве получателя - широковещательный адрес (FF:FF:FF:FF:FF:FF), в качестве отправителя - MAC-адрес интерфейса устройства, пытающегося выяснить IP
- на сетевом - собственно ARP запрос, в нем содержится информация о том, какой IP и кем ищется. 
3) Коммутатор, на который попал кадр, рассылает его копии во все порты этого влана (того, которому принадлежит изначальный хост), кроме того, откуда он получен.
4) Все устройства, получив этот кадр и, видя, что он широковещательный, предполагают, что он адресован им.
5) Распаковав кадр, все хосты, кроме маршрутизатора, видят, что в ARP-запросе не их адрес. А маршрутизатор посылает unicast’овый ARP-ответ со своим MAC-адресом.
6) Изначальный хост получает ARP-ответ, теперь у него есть MAC-адрес шлюза. Он формирует пакет из тех данных, что ему нужно отправить на 172.16.4.5. В качестве MAC-адреса
получателя ПК ставит адрес шлюза. При этом IP-адрес
получателя в пакете остаётся 172.16.4.5

7) Кадр посылается в сеть, коммутаторы доставляют его на маршрутизатор.
8) На маршрутизаторе, в соответствии с меткой влана, кадр принимается конкретным сабинтерфейсом. Данные канального уровня откидываются
.
9) Из заголовка IP-пакета, рутер узнаёт адрес получателя, а из своей таблицы маршрутизации видит, что тот находится в непосредственно подключенной к нему сети на определённом сабинтерфейсе (в нашем случае FE0/0.102).
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
10) Маршрутизатор отправляет ARP-запрос с этого сабинтерфейса - узнаёт MAC-адрес получателя.
11) Изначальный IP-пакет, не изменяясь
инкапсулируется в новый кадр
, при этом:
12) Кадр доставляется коммутаторами до хоста-получателя.
Будет она вот такой:
То есть прибавляются две точки в Санкт-Петербурге: небольшой офис на Васильевском острове и сам завод в Озерках - и одна в Кемерово в районе Красная горка. Для простоты у нас будет один провайдер “Балаган Телеком”, который на выгодных условиях предоставит нам L2VPN до обеих точек. В одном из следующих выпусков мы тему различных вариантов подключения раскроем в красках. А пока вкратце: L2VPN - это, очень грубо говоря, когда вам провайдер предоставляет влан от точки до точки (можно для простоты представить, что они включены в один коммутатор).
Следует сказать несколько слов об IP-адресации и делении на подсети. В нулевой части мы уже затронули вопросы планирования, весьма вскользь, надо сказать. Вообще, в любой более или менее большой компании должен быть некий регламент - свод правил, следуя которому вы распределяете IP-адреса везде. Сеть у нас сейчас разрастается и разработать его очень важно.
Ну вот к примеру, скажем, что для офисов в других городах это будет так: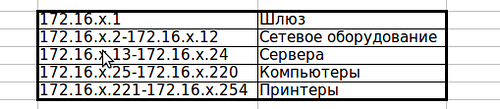
Это весьма упрощённый регламент, но теперь мы во всяком случае точно знаем, что у шлюза всегда будет 1-й адрес, до 12-го мы будем выдавать коммутаторам и всяким wi-fi-точкам, а все сервера будем искать в диапазоне 172.16.х.13-172.16.х.23. Разумеется, по своему вкусу вы можете уточнять регламент вплоть до адреса каждого сервера, добавлять в него правило формирования имён устройств, доменных имён, политику списков доступа и т.д. Чем точнее вы сформулируете правила и строже будете следить за их выполнением, тем проще разбираться в структуре сети, решать проблемы, адаптироваться к ситуации и наказывать виновных. Это примерно, как схема запоминания паролей: когда у вас есть некое правило их формирования, вам не нужно держать в голове несколько десятков сложнозапоминаемых паролей, вы всегда можете их вычислить. Вот так же и тут. Я некогда работал в средних размеров холдинге и знал, что если я приеду в офис где-нибудь в забытой коровами деревне, то там точно x.y.z.1 - это циска, x.y.z.2 - дистрибьюшн-свитч прокурва, а x.y.z.101 - компьютер главного бухгалтера, с которого надо дать доступ на какой-нибудь контур-экстерн. Другой вопрос, что надо это ещё проверить, потому что местные ИТшники такого порой наворотят, что слезами омываешься сквозь смех.
Было дело парнишка решил сам управлять всем доступом в интернет (обычно это делал я на маршрутизаторе). Поставил proxy-сервер, случайно поднял на нём NAT и зарулил туда трафик локальной сети, на всех машинах прописав его в качестве шлюза по умолчанию, а потом я минут 20 разбирался, как так: у них всё работает, а мы их не видим.
Почему это так? И как вообще понять все эти маски подсетей? В рамках одной статьи мы не сможем этого рассказать, иначе она получится длинная, как палуба Титаника и запутанная, как одесские катакомбы. Крайне рекомендуем очень плотно познакомиться с такими понятиями, как IP-адрес, маска подсети, их представления в двоичном виде и CIDR (Classless InterDomain Routing) самостоятельно. Мы же далее будем только аргументировать выбор конкретного размера сети. Как бы то ни было, полное понимание придёт только с практикой.
Вообще, очень неплохо эта тема раскрыта в этой статье: http://habrahabr.ru/post/129664/
В данный момент (вспомним ) у нас в Москве использованы адреса 172.16.0.0-172.16.6.255. Предположим, что сеть может ещё увеличиться здесь, допустим, появится офис на Воробьёвых горах и зарезервируем ещё подсети до 172.16.15.0/24 включительно.
Все эти адреса: 172.16.0.0-172.16.15.255 - можно описать так: 172.16.0.0/20. Эта сеть (с префиксом /20) будет так называемой суперсетью
, а операция объединения подсетей в суперсети называется суммированием
подсетей (суммированием маршрутов, если быть точным, route summarization)
Приносим извинения за гигантские простыни, видео тоже с каждым разом становится всё длиннее и невыносимее. Постараемся в следующий раз быть более компактными.







